NeuroShell Classifier
The NeuroShell Classifier was crafted from the beginning to
excel at solving classification and decision making problems. NeuroShell
Classifier can detect categories in new data based upon the categories it
learned from case histories. Outputs are categories such as {cancer,
benign}, {buy, sell, hold}, {acidic, neutral, alkaline}, {highly qualified,
qualified, unqualified}, {winner, loser}, {product 1, product 2, … , product
N}, {decision 1, decision2, … , decision N}. Like the NeuroShell Predictor,
it has the latest proprietary neural and genetic classifiers with no
parameters to set. These are our most powerful neural networks. It reads and writes
text files.
The classification algorithms are the crowning achievement of several years
of research. Gone are the days of dozens of parameters that must be
artistically set to create a good model without over-fitting. Gone are the
days of hiring a neural net expert or a statistician to build your
predictive models.
Two of the most commonly heard complaints about previous classification
systems, aside from being too hard to use, are that they are too slow or
that they do not accurately tell you how important each of the variables is
to the model. We've taken care of those problems. That's why we have two
training models from which to choose:
1. The first training method, which we call the “neural method” is based on
an algorithm called Turboprop2, a variant of the famous Cascade Correlation
algorithm invented at Carnegie Mellon University by Scott Fahlman.
TurboProp2 dynamically grows hidden neurons and trains very
fast. TurboProp2 models are built (trained) in a matter of seconds compared
to hours for older neural networks types.
2. The second method, the “genetic training method”, is a genetic algorithm
variation of the Probabilistic neural Net (PNN) invented by Donald Specht.
It trains everything in an out-of-sample mode; it is essentially doing a
"one-hold-out" technique, also called "jackknife" or "cross validation". If
you train using this method, you are essentially looking at the training set
out-of-sample. This method is therefore extremely effective when you do not
have many patterns on which to train.
The genetic training
method takes longer to train as more patterns are added to the training set.
The genetic method provides an analysis of independent
variables (inputs) to help you determine which ones are most important in
your model.
The NeuroShell Classifier is so easy to use that it doesn't need a manual!
Instead, there is an "Instructor" that guides you through making the
classification models. At every stage of the Instructor, our extensive help
file will give you all the information you need. When you have learned from
the Instructor, you can turn it off and work from the toolbar or menus. The
program does includes an on-line, context sensitive reference manual that you
may print yourself or just browse from your computer.
Finally, for those who want to embed the resulting neural models into your
own programs, or to distribute the results, there is an optional
Run-Time Server available. Classifier models may be distributed without
incurring royalties or other fees.
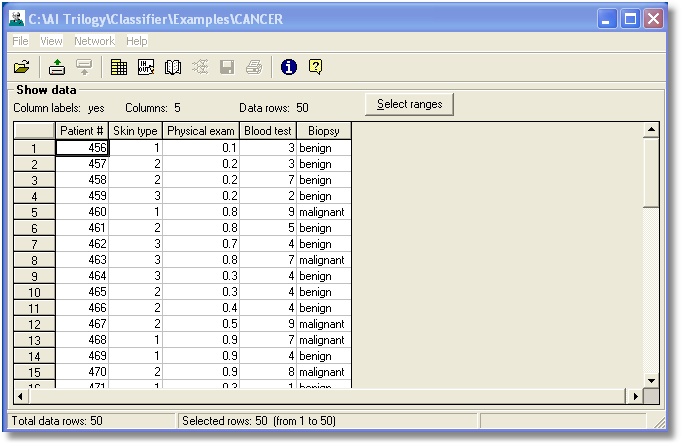
The NeuroShell
Classifier reads data exported from spreadsheets and displays it in a
datagrid.
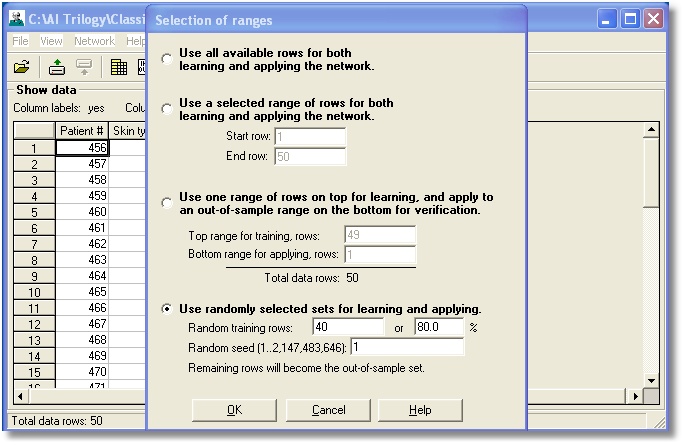
You can select contiguous or
random data rows for training and out-of-sample sets.
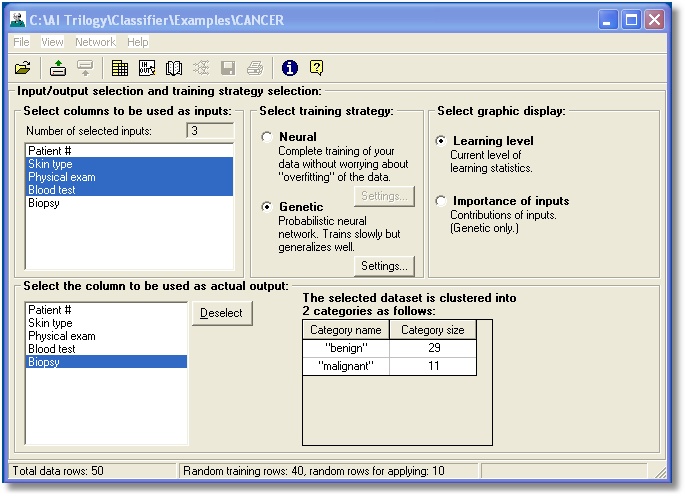
You can select inputs and the
desired output from the columns in your data file. You can also select either
the neural or genetic training method.
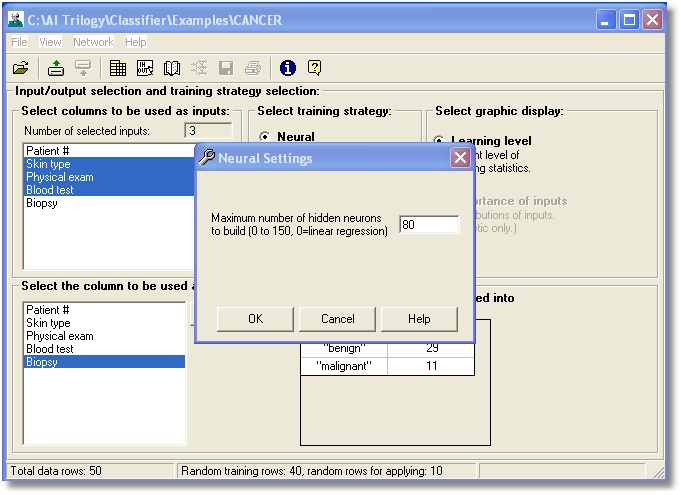
There is only one setting the
neural method requires, unlike the older backpropagation algorithm which
required extensive “parameter tweaking”.
The genetic training method
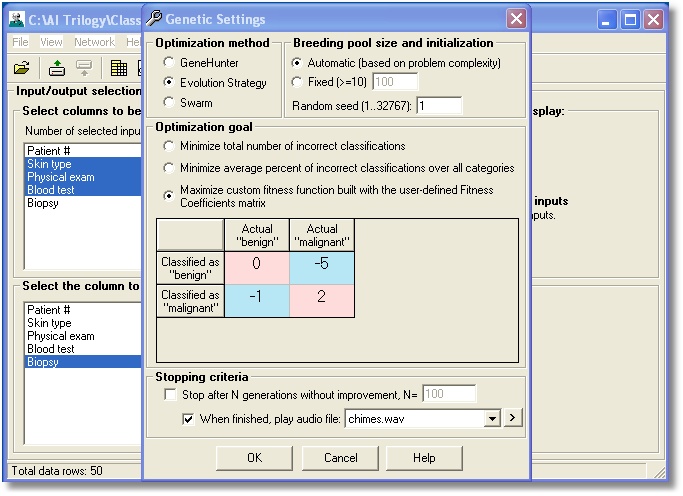
offers three modern optimization techniques and a choice of optimization goals.
The custom fitness matrix allows you to penalize of emphasize some
classification errors and successes, for example, to penalize false negatives
more than false positives.
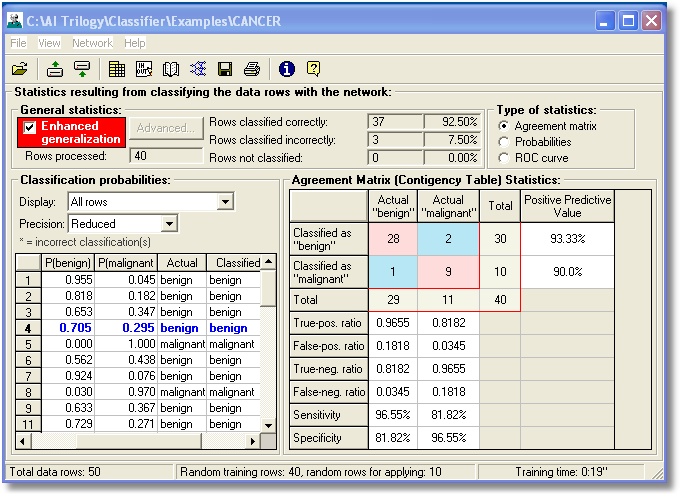
After training, the neural network may
be applied to training data or out-of-sample data with a variety of statistics
appropriate for classification.
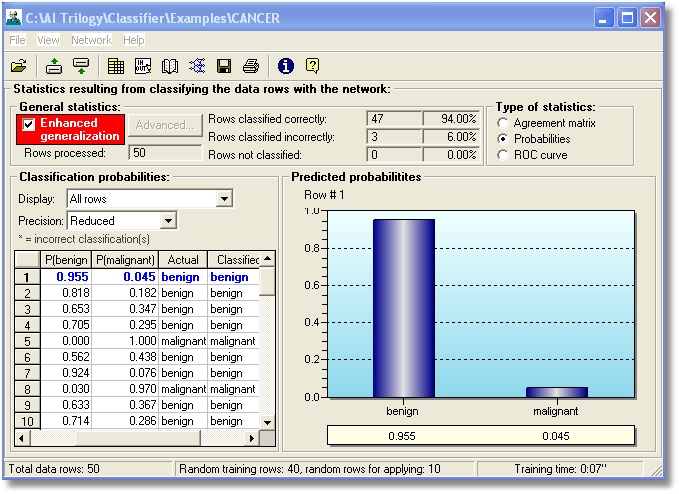
Classifications are made on the
basis of probabilities. If you wish, you can interpret the probabilities in
different ways.
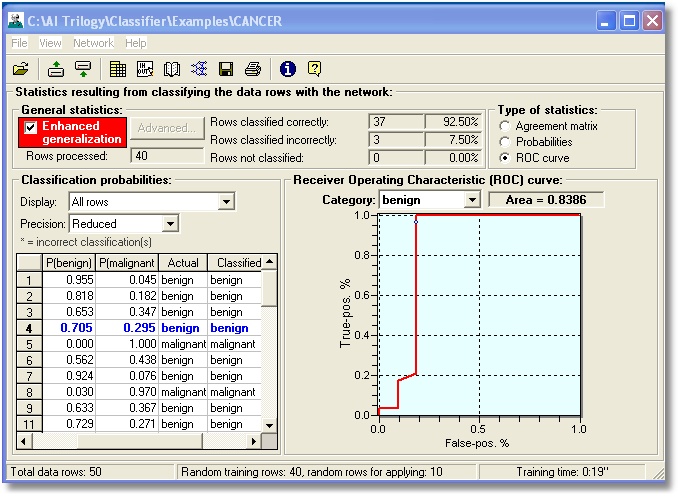
Receiver – operator
characteristic curves are a popular graphic way to summarize the overall
efficiency of the classification model.
|
